October 17, 2024
PDF-WuKong,a multimodal largelanguagemodel(MLLM)based on domestic chips, is launched recently. It is developed byProfessor Bai Xiang's teamandresearchers from Huawei.

(Title of the paper:PDF-WuKong:A Large Multimodal Model for Efficient Long PDF Reading with End-to-End Sparse Sampling)
PDF-WuKong not only addresses the technical challenges faced by existingMLLMsin processing long PDFdocuments,but also outperforms several well-known international closed-source commercial products. Itshowsthe capabilities of domestic chips in supporting complex large model applications.
How complex isitfor AI model to process long PDF documents?
Long PDF documents contain multimodal content,includingtexts, charts, and formulas,which isdifficult for existing AI models toprocess.There are twoexistingmethods: plaintext modalityand purelyvisualmodality.
Plain textmodality converts all information into text, which can handle long documents,butitlacksmultimodal understanding of visual elements;
Purelyvisual modality excels at processing images and visual layouts but incurs high computational costs and finds it difficult to capturethe interrelationshipin multi-page documents.
Moreover, existing document question-answering datasets are mostly limited to single-page documents or single-evidence questions, lacking complex multi-evidence reasoning scenarios, which makes it challenging to evaluate the model's ability toprocesslong documents.
These limitations hinder AI models' performance when dealing with multi-page PDF documents
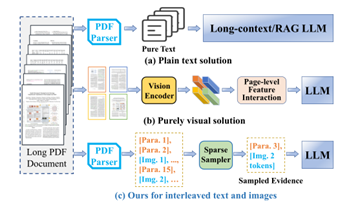
(Methods that traditional AI models used for long multi-page PDF document understanding)
How to break the limitations of AI models in processing multi-page PDFs?
1.PDF-WuKong Model
PDF-WuKong modelis introduced in the paper,which isdesigned to achieve multimodal understanding of long PDF documents and overcome the limitations of existing models that treat PDFs as a single modality.
Its core structure includes:
1)Document Parsing: Parsing PDF documents into structured contentsthatmatchescorrectreading orderof humans,includingtextblocksand images.
2)Sparse Sampling: Calculating the similarity between users’ queries and various parts of the document to select the most relevant text paragraphs and image blocks from cached embeddings, which are then passed to subsequent model parts.
3)Answer Generation: Feeding the selected key information along with the question and instructions intothelarge model to generate accurate answers. PDF-WuKong optimizes the sparse sampler andLLMin an end-to-end manner, improving both the efficiency of long document processing and the model's interpretability.
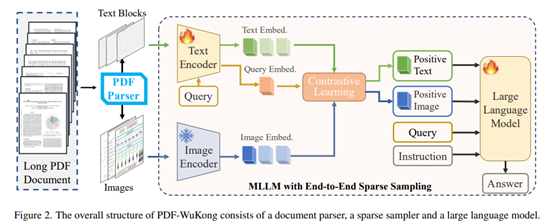
(The overall structure of PDF-WuKong)
2.PaperPDF Dataset
Sinceexisting datasetsareconfined to single-page documents or single-evidence questions, thispaper proposes a high-quality question-answer pair generation method and subsequently constructs the PaperPDF dataset. This method includes four main steps:
1)StructuredParsing:EmployingGrobid to parseabout89,000 arXiv papers, breaking them down into multiple textchunks(e.g., paragraphs) and imagechunks (e.g., charts).
2)Rule-basedExtraction: Randomly selecting a subset of parsed text blocks and imagesusing predefined rules.
3)PromptConstruction: Constructing generation prompts based on different types of question-answer data and feeding them into existinglarge multimodal model products (e.g., Gemini, GPT-4v) to produce corresponding questions and answers.
4)Filtering: Applying aset ofrules to filter thegeneratedtraining setswhilechecking the testingsetsmanually.
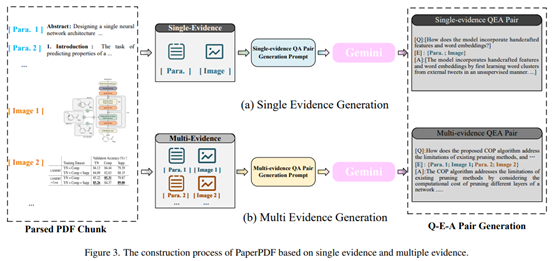
(The construction process using PaperPDF dataset)
What is the significance of PDF-WuKong?
PDF-WuKong is the firstMLLMfor long documents based on domestic chips, pioneering an efficient solution for understanding and processing lengthy PDF documents containing substantial text and image information, especially given the constraints on input window length for multimodal large models.
Additionally, itproposes a high-quality method for generating long document QA pairsalong with anopen-sourced corresponding dataset, PaperPDF.Therefore, itprovidesstrong support for future research and application exploration in long document understanding and multimodal retrieval.

