March 19, 2024
Large multimodal models (LMMs) are a type of AI architecture that are able to process and integrate various perceptual data simultaneously, which perform greatly across numerous scenarios. With their abundant knowledge and outstanding chatting abilities, LMMs can understand and perceive the world in depth like human beings. The Monkey LMM was developed by Professor Bai Xiang’s team and researchers from Kingsoft Office. Recently, the paper introducing the Monkey LMM has been accepted at CVPR 2024, a top-level international conference in artificial intelligence. The model also ranks the first among open-source LMMs in OpenCompass (an evaluation system verified by Meta AI) LMM leaderboard. TextMonkey is an upgraded version of Monkey for text-centric tasks, which breaks through the boundaries of general document understanding capabilities. It makes remarkable progress in more than 12 benchmarks, including Scene Text recognition, office document summarization, mathematical question answering, document layout analysis, table understanding, chart VQA, and key information extraction. Additionally, it has made significant advancements on OCRBench, the largest and most comprehensive document image intelligent dataset in the world. TextMonkey outperforms other open-source methods in general document understanding.
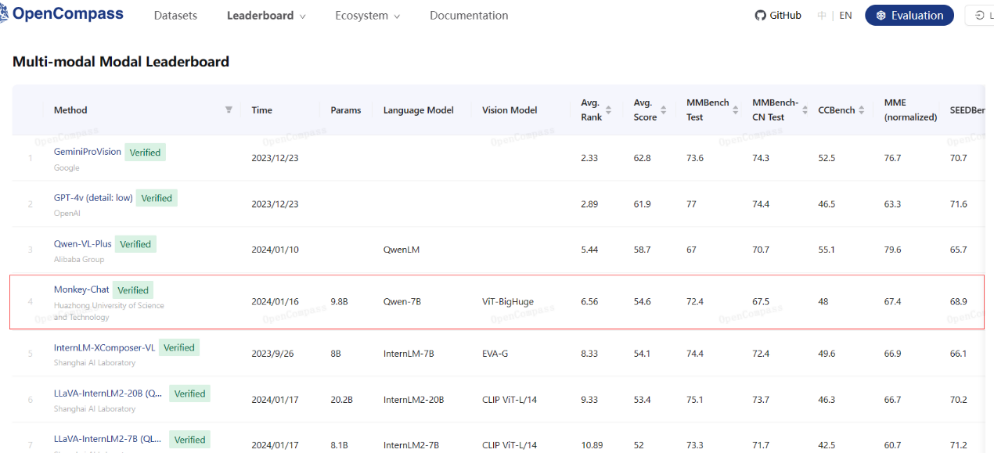
Figure 1. Multi-modal model leaderboard on OpenCompass
The success of TextMonkey attributes to its ability to simulate human visual cognition, which enables it to naturally recognize the interconnections of the parts in high-definition document images, and sensitively identify key elements within the image. Furthermore, based on its in-depth understanding of users’ needs, TextMonkey provides more accurate answers through text positioning techniques, which improves the interpretability of the model, reduces hallucinations, and effectively handles all types of document tasks with great performance.
TextMonkey can help us structuralize charts, tables, and other documents. It transforms images into a lightweight data-exchange format for easy recognition and extraction.
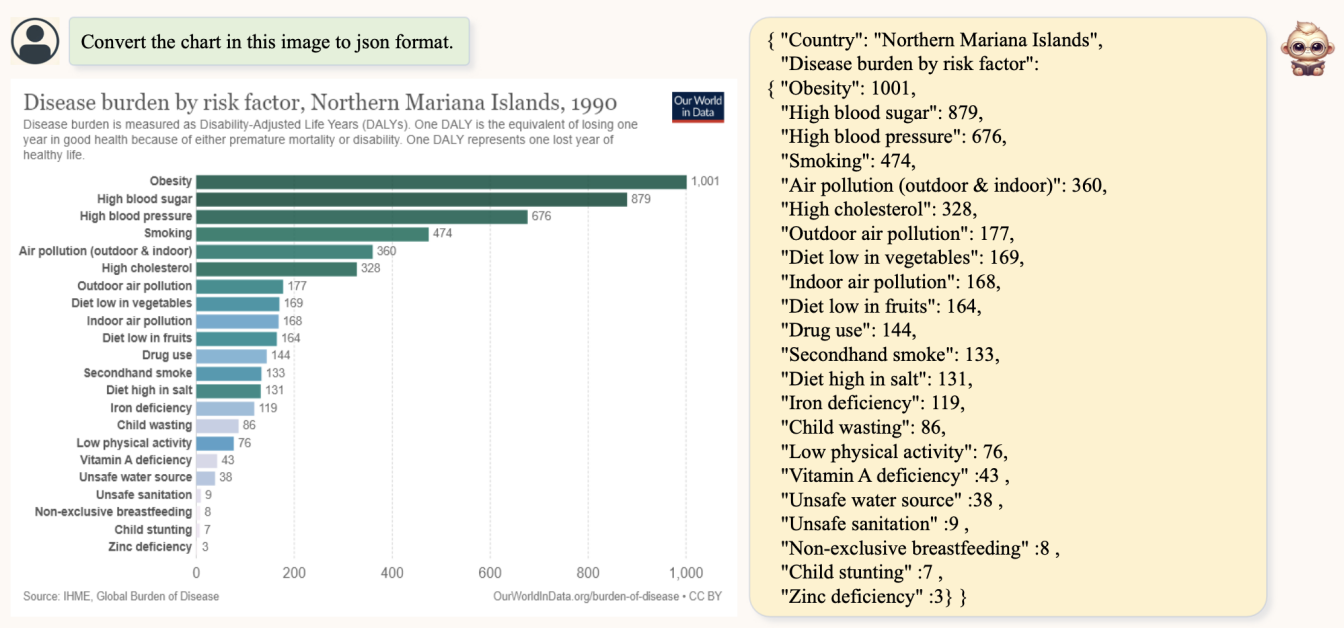
Figure 2. An example of structuralization of a chart into json using TextMonkey
TextMonkey can also serve as an agent for smartphone applications, requiring no back-end interaction. With just voice input and screenshots, it can simulate human behavior to click and perform various tasks on the smartphone, and autonomously control the apps.
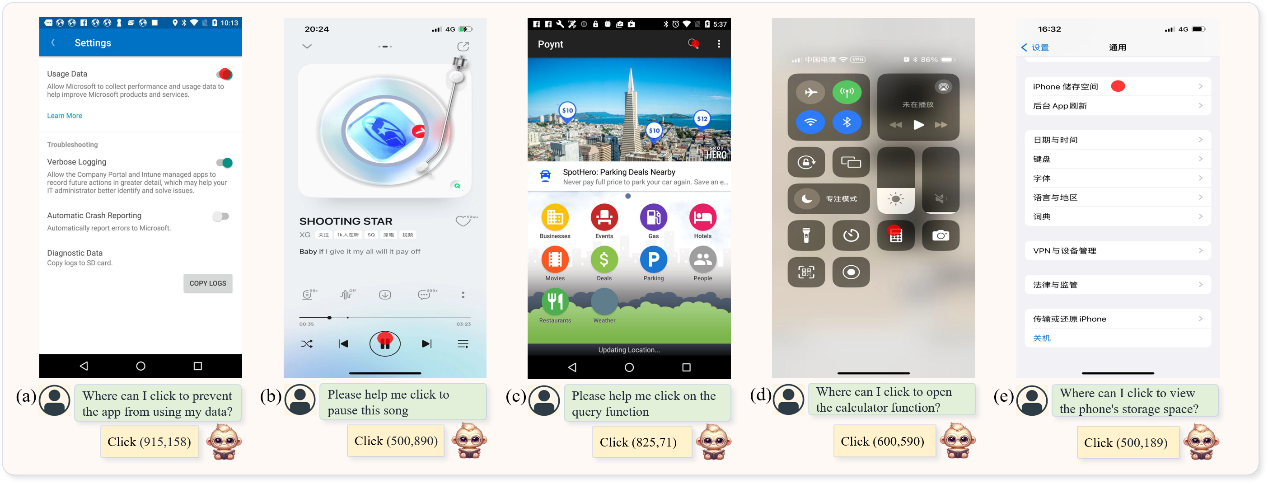
Figure 3. TextMonkey serving as an agent for smartphone app
It can also help us solve math problems and provides us with steps.
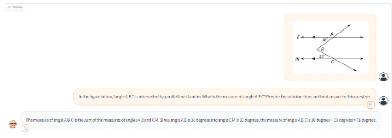
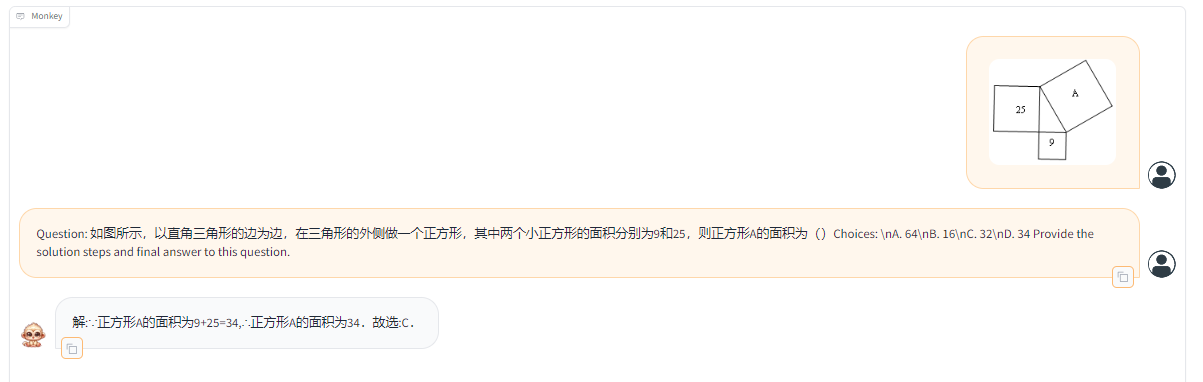
Figure 4. TextMonkey solves math problems and provides specific steps
Currently, as enterprises are accelerating digital transformation, the multimodal structuralized analysis and content extraction of documents and images have become particularly crucial. From casually captured images, electronic documents and office software files to analytical reports, the ability to process data accurately, rapidly and automatically is essential to enhance the productivity of enterprises. Against this backdrop, TextMonkey offers an innovative choice to solve problems universally, and it is expected to make technological breakthroughs in areas such as office automation, smart education, and smart finance. We are seeing new hope for a comprehensive improvement on general document comprehension.
Code:https://github.com/Yuliang-Liu/Monkey
View article:https://arxiv.org/abs/2403.04473
DEMO:http://vlrlab-monkey.xyz:7684

