The surge in research on multimodal large language models (MLLM) was sparked by GPT-4’s demonstration of powerful multimodal capabilities. Multimodal large language models, integrating text and visual processing abilities, are advanced AI systems designed to mimic human perception. They combine images and language for understanding and reasoning, considered a crucial step towards general artificial intelligence. In November, Prof.Bai Xiang’s team released a new multimodal large language model — Monkey.

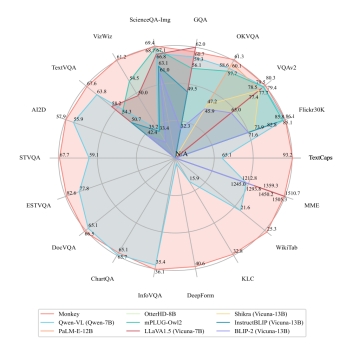
Focusing on high resolution, Monkey processes images with resolutions up to 1344x896. Trained on large-scale, high-quality image-text data with detailed descriptions, Monkey developed keen insights into image details, achieving state-of-the-art (SOTA) results in 16 datasets related to Caption and QA tasks. It even performs impressively in dense text question-answering tasks compared to GPT4V.
Monkey’s robust Q&A capability accurately grasps questions and provides correct answers, particularly excelling in dense text Q&A tasks, a challenge for current large language models. Monkey offers a viable solution to this problem.
In their exploration, Prof.Bai Xiang’s team proposed two methods:
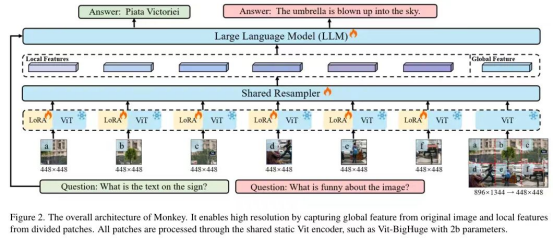
1. Increasing input resolution.
By cropping the original input image into multiple blocks and resizing these blocks and the original image to 448x448. Each block, during visual encoding, includes a unique Lora to better extract local visual features. Training focuses only on the Lora part, while the original input image is used for extracting global features. This method achieves the purpose of increasing input resolution.
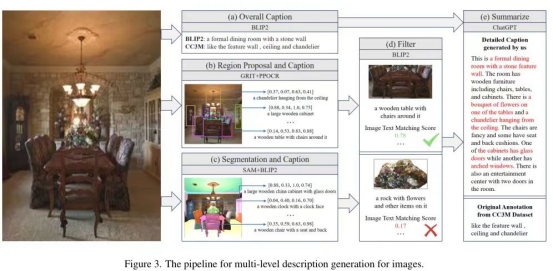
2. A detailed description generation method for multi-level feature fusion to create high-quality image-text data.
It consists of five steps: First, using BLIP2 to generate a global description of the entire image; second, using GRIT to generate regional boxes, providing names and detailed descriptions of objects in the region, and using PPOCR to extract text box coordinates and content; third, using SAM for segmentation, and inputting into BLIP2 to generate detailed descriptions of each object and its components; fourth, using BLIP-2 to filter out low-scoring matches; finally, using ChatGPT to summarize the descriptions obtained to produce a detailed description of the image.
Through the synergistic effect of these two designs, Monkey achieved remarkable results in multiple benchmark tests. Testing on 18 different datasets showed that Monkey has exceptional performance. In dense text Q&A tasks, it can reason according to the question’s requirements, adapting to Chinese Q&A. In scenarios with less text, its rich knowledge base allows it to extrapolate and provide correct answers. In Caption tasks, it not only accurately and detailedly describes images but also reasonably diverges, analyzing some abstract meanings conveyed by the images. These demonstrate Monkey’s capability in image description generation, scene Q&A, visual Q&A centered on scene text, and document-oriented visual Q&A tasks.

